
Kappa Architecture:以資料為中心的系統架構
在開發軟體時,有許多眾所周知的架構模式(architecture pattern)可做為參考。例如最廣為人知的 MVC 架構。採用這些常用模式,能大幅減低溝通成本,各種 Framework 也能提高開發速度。
現在已經是個以資料為中心的環境,各種商業決策都依賴大量的資料。因此,系統必須能提供各種資料格式與查詢方式供各種需求使用。在這樣的環境中,也慢慢發展出許多特有的模式。
常見的狀況是,一個系統中不同的角色有著不同的需求。工程師希望能採用高效能,容易擴充的架構;業務部門希望能即時查到各種資訊;會計系統希望能收到批次處理的當月報表。這些不同的需求,都在不斷的拉扯一個系統的架構。
如果是較為單純的系統,所有資料都會存在單一資料庫中。常常,為了應付各種互相衝突的需求,資料的格式(schema)被不斷修改、欄位越來越多。最後各部門的需求互相糾結,整個系統陷入泥沼,開發速度大減。只使用單一資料庫又無法滿足各種需求,只好導入 ElasticSearch 做全文檢索與 Hadoop/Spark 進行大量資料處理,即時資料處理也需要與批次處理完全不同的架構。於是,整個系統益加複雜,難以維護。
遇到這種狀況,許多人都會將系統按照業務領域切開,切成一個一個的 microservices。每個 service 有著自己專用的資料儲存架構,便可解決共用資料庫的糾結狀況。
以電商系統為例,系統將會被拆成「訂單服務」、「客戶分析服務」、「帳務服務」等獨立的服務組成。服務之間只透過 API 來溝通,避免過度耦合。
不過,由於各個服務之間需要不斷的互相溝通與交換資料,每個服務對資料也有不同的查詢需求。隨著需求不斷變動,每個子服務所提供的 API 還是會變的越來越複雜。
各服務為了避免 API 的麻煩,會希望自己也有一份資料副本可隨意使用。一旦資料有了副本,就要處理許多資料同步的麻煩問題。
無論如何,這些狀況都只會讓系統再度糾結在一起,原本按領域切割好的服務實際上又合而為一。遇到這種情況時,通常代表服務的界線需要做調整。但調整服務界線從來就不是一件簡單的事。
假設有兩個部門都會對訂單進行各種分析。理想中,應該切出一個分析服務來服務這兩個部門。然而受限於組織架構(head count 分配、預算規劃、政治等),最後多半是兩個部門有各自的分析服務。因此大幅提高系統開發成本,產生許多重複的工作。
康威定律(Conway’s Law)便是描述這個現象:系統的架構就等於組織的架構。如果已有組織架構存在,那就很難設計出打破原先組織架構的系統架構。
於是,系統架構被組織架構所限制。無法劃分出正確的服務分界,便無法建立真正有彈性的系統架構
問題的本質:資料的流通性
實際上,這些問題其實只是同一問題的不同面向。也就是「資料在領域間轉換的複雜度」。
- 不同業務領域需要的資料結構大不相同,所以單一資料庫提供的單一 schema 無法負荷。
- 團隊在有限資源下,難以應付不同領域的需求,導致無法設計容易維護與使用的 API。
- 讓資料在不同領域間流動的成本太高,所以資料出現大量、可能過時的副本。
- 領域間差異太大,導致部門間溝通困難,因此組織架構影響系統架構決策,與系統架構互相糾結、牽制。
而 Kappa 架構便是藉由回歸資料的本質來解決這些問題。
資料的本質:Append-only Log
任何資料都是由一連串的改變所形成,因此,每一筆資料都可以用一個 append-only log 表示。
假設目前有一筆用戶資料如下:
{
"user_id": 1234,
"username": “Jack123”,
"balance": 75
}
這筆用戶資料其實是由一連串的事件修改所形成:
{ // 使用者註冊
"event": "register",
"username": "Jack123",
"user_id": 1234,
}
{ // 使用者儲值
"event": "deposit",
"user_id": 1234
"add_balance”: 100
}
{ // 使用者消費付款
"event": "purchase",
"user_id": 1234,
"add_balance": -25
}
因為已經發生的修改不會再變動,因此這是一份 append-only log。
用 append-only log 來記錄資料有什麼好處呢?因為相較於展開後的欄位,「修改」的格式非常單純,只由「修改時間」、「欄位」、「更改的值」等欄位所構成,資料格式穩定,省下了修改 schema 的困擾。
然而,這樣的資料結構並不容易使用。缺乏關連,難以查詢,也少了很多驗證正確性的工具。該怎麼辦呢?
Kappa 架構
既然任何資料都可以用一連串的改變來表示,那這一連串的改變也自然可以轉換成任何一種資料格式。
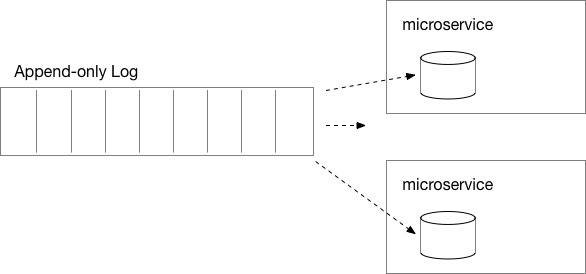
Kappa 架構的核心概念便在此:用記錄改變的 append-only log 來當作系統的資料核心,各 microservices 根據 log 的新增,將資料存成自己所需要的格式。需要資料關連性跟方便的 SQL?那就把資料寫進 RDBMS。需要全文檢索?那就把資料放進 elasticsearch。
這樣的作法很類似許多資料庫提供的「Materialized View」的功能:將資料放進一個結構方便使用的暫時空間中。
只要每個服務不去刻意修改 view 中的資料,那就隨時都可以從 log 重建這份 view,也就避免了副本不同步的問題。如果 view 的資料格式需要修改,只要直接整個服務砍掉,從 log 重建一份即可。
於是,每個服務都能自行取用最原始的 log,轉成最適合的格式。服務可以專心提供他專有的價值,而不需要負責資料的流動。
因為這些性質,系統變的更容易維護,服務隨時可以重啟,不用擔心資料損失。架構上也更加單純,不論業務需要的是即時串流分析,或是批次處理,都能自由選擇適用的儲存方式,而不用擔心資料同步問題,也不需分開維護兩套系統。
重播
Kappa 架構還有另一個好處:資料的所有變動都被紀錄了下來,因此不再受到「當下」這個時間所限制。
如果突然需要追蹤去年三月到四月的整體資料變化,因為所有紀錄都被紀錄在集中的 append-only log 中,只要 log 還有被保存著,就能針對需要的時間區間的 log 啟動需要的服務,讓服務重播(replay)這些資料,便可得到當時的系統狀態。
Microservices 不再侷限於「現在」,而是只要給他一段能重播的 log,他就能重現當時的狀態。整個系統變的更有彈性、更容易擴充。
以後遇到資料密集的系統時,Kappa 這樣的架構也許能幫你省下不少心力。
I have a (rarely updated) email newsletter for reasons I've forgotten