一切都是為了效能
故事要從 boxed value 跟 unboxed value 說起。
所謂的 boxed value 是指:不直接存取 primitive value,而是透過指標來操作數值。近代的程式語言常常都用這種方法操作資料。而 unboxed value 就是指直接操作值,不經過一層指標。

為什麼要用 boxed value 呢?因為近代程式語言都提供物件、function 等等一定會透過指標來操作的資料。將所有資料統一包(box)在指標後,讓系統處理泛型(generic)時變得更加一致。如果你寫過 Java 應該就有體驗過這種設計,為了解決 boxed/unboxed value 之間麻煩的轉換,auto-boxing 也是常見的功能。
當然,這多出來的一層指標並不是免費的。
效能的損失
以浮點數做為例子。現代系統架構都提供浮點數專屬的指令集來加速計算,譬如說,在 x86 上你可以用 faddp、 fdivp 之類的指令,讓 FPU硬體幫你計算。一旦多了一層指標,每次計算前都要 deref 一次,多出許多重複的工作。
另外,這些包裝不是只有指標,還包含了底下 value 的型別。因此使用的記憶體也會變多。
NaN Tagging
有沒有辦法讓 primitive value 跟其他 boxed value 用同樣的結構儲存,避免效能損失,又能讓系統更簡單呢?LuaJIT 用 NaN Tagging 來解決這個問題。
要搞懂 NaN Tagging 前,先來複習一下 IEEE 754 Floating Point 的定義。IEEE 754 的 64bit floating point (double) 的格式如下,第一個 bit 是 sign,接著 11 個 bit 的指數,最後是52 bit 的分數。

IEEE 754 可以表示特別的數值,像是 NaN 或是無限大。而 NaN 的格式是:指數全為 1,尾數小數不全為 0。

這時你可能會注意到,有很多種數值都代表 NaN,畢竟後面 52-bit 只要不全是 0 就可以。
而硬體的 FPU 在產生 NaN 時,只會產生 0xfff8_0000_0000_0000 這種 NaN,剩下都沒用到!

於是,NaN Tagging 誕生了。
因為所有 most-significant word(高位 4 byte)比 0xfff8_0000 大的浮點數都可以自由使用。LuaJIT 將這些浮點數用來儲存他的資料。只用 64bit 就能儲存所有 primitive value 跟 boxed value。像是 Nil、True、False 就表示成:
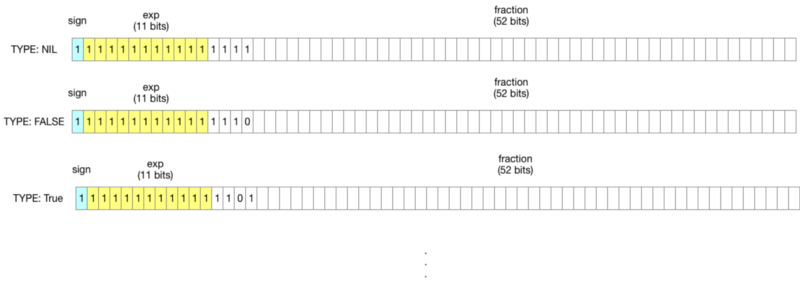
如果需要儲存指標,後面 ~48 bit 對於 64bit 系統的指標而言綽綽有餘。
於是,NaN tagging 讓我們省下了額外一層的指標。型別的定義跟判斷型別的方式也變的非常簡單:
這樣做,讓所有的 primitive value 都能直接被存取,不需要經過指標。而其他型別也能用同樣的 64-bit 空間儲存,產生許多優化的可能性,也能更加善用 register。
其實這並不是 LuaJIT 獨創的技巧,據說早在 80, 90 年代的許多 Lisp 實做就有用到 NaNtagging。透過結合對硬體實做的理解跟軟體的設計,讓 LuaJIT 相對於其他動態語言,能搾出更多的效能。